






Data cleaning techniques in data science involve identifying and correcting errors in a dataset to ensure accuracy. Data cleaning is a crucial step in the data science process that involves identifying and rectifying errors, inconsistencies, and inaccuracies in a dataset.
These errors can stem from various sources such as human error, equipment malfunction, or data corruption during transmission. By employing effective data cleaning techniques, data scientists can enhance the quality and reliability of the data, leading to more accurate analysis and valuable insights.
This process often includes handling missing data, removing duplicates, correcting inconsistencies, and ensuring data is formatted correctly. Ultimately, thorough data cleaning lays a solid foundation for robust and reliable data analysis in data science projects.
The Importance Of Data Cleaning
Data cleaning techniques in data science are crucial for ensuring accurate analysis and reliable insights. By removing errors and inconsistencies, data cleaning enhances the quality and reliability of the final results, leading to better decision-making and improved business outcomes.
Boosting Data Accuracy
Data cleaning, also known as data cleansing or data scrubbing, plays a crucial role in boosting data accuracy in data science. By eliminating inconsistencies, errors, and inaccuracies from datasets, data cleaning ensures that the data used for analysis and decision-making is reliable and trustworthy.
Improving Decision Making
High-quality data is essential for making informed decisions in data science. Data cleaning techniques help in improving decision-making by ensuring that the data used as the basis for decision-making is accurate, complete, and consistent. By removing duplicate records, filling in missing values, and rectifying errors, data cleaning enhances the reliability of the data, allowing data scientists to make more accurate and confident decisions.

Credit: www.analyticsvidhya.com
Identifying Common Data Quality Issues
Discovering common data quality issues is crucial in data science. Implementing effective data cleaning techniques ensures accurate analysis and reliable insights. Identifying and addressing these issues early on optimizes the quality and integrity of the data for informed decision-making.
Identifying Common Data Quality Issues is a crucial step in data cleaning in Data Science. It involves detecting and addressing issues that are commonly found in datasets. Some of the most common data quality issues include missing values, duplicate data, and inconsistent data. In this section, we will explore each of these issues in more detail and discuss techniques for dealing with them effectively.Missing Values
Missing values are a common data quality issue that can occur for various reasons, including data entry errors, incomplete data, or data loss during transmission. Incomplete data can lead to biased analysis and can affect the accuracy of models built on the dataset. One of the ways to handle missing values is to remove the entire row that contains the missing value. However, this can lead to a significant loss of data. Another way is to impute the missing values with the mean, median, or mode of the feature. Imputing missing values can help to preserve the integrity of the data and prevent data loss.Duplicate Data
Duplicate data is another common data quality issue that can occur when the same data is recorded multiple times or when data is copied from different sources. Duplicate data can lead to inaccurate analysis and can skew the results of data models. One way to handle duplicate data is to remove the duplicates entirely. This can be done by identifying the duplicates and selecting the first occurrence of the data. Alternatively, you can merge the duplicates by taking the mean or median of the values. This can help to preserve the integrity of the data and prevent data loss.Inconsistent Data
Inconsistent data is a data quality issue that occurs when data is recorded differently in different instances or when different data sources use different formats. Inconsistent data can lead to inaccurate analysis and can affect the results of data models. One way to handle inconsistent data is to standardize the data by converting it to a common format. This can be done by using regular expressions or by using data cleaning tools that can detect and correct inconsistencies automatically. Standardizing the data can help to ensure consistency across the dataset and improve the accuracy of analysis and modeling.Initial Steps In Data Cleaning
When it comes to data cleaning in data science, the initial steps are crucial for ensuring the accuracy and reliability of the data used for analysis. Data cleaning involves various techniques and processes to identify and rectify errors, inconsistencies, and inaccuracies in the dataset. In this section, we will delve into the key initial steps in data cleaning, including data auditing and workflow creation.
Data Auditing
Data auditing involves a comprehensive examination of the dataset to identify any anomalies, missing values, outliers, and inconsistencies. It is essential to conduct thorough data auditing to gain insights into the quality and integrity of the data. This process helps in uncovering potential issues that may impact the analysis and decision-making based on the data.
Workflow Creation
Workflow creation entails the development of a systematic plan for data cleaning, outlining the sequence of steps and tools to be used. It involves creating a structured framework for data validation, transformation, and standardization. Establishing a well-defined workflow is essential for streamlining the data cleaning process and ensuring consistency in the treatment of data across different sources and formats.
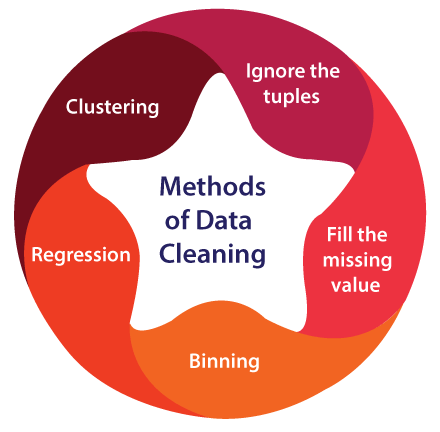
Credit: www.javatpoint.com
Handling Missing Values
Data cleaning in data science involves handling missing values to ensure accurate analysis and modeling. Techniques such as imputation and deletion are used to address missing data, maintaining the integrity of the dataset for reliable insights and decision-making.
Deletion
When handling missing values, one approach is to delete rows or columns with missing data.
Imputation Techniques
Another method is to impute missing values using statistical techniques.
Dealing with missing data is crucial in data science to ensure accurate analysis and model building.
Missing values can skew results and lead to erroneous conclusions, hence the importance of proper handling.
Dealing With Duplicate Data
Duplicate data can be a major challenge in data science. Implementing effective data cleaning techniques is crucial to ensure accurate analysis and insights. By identifying and eliminating duplicate entries, data scientists can optimize their models and make better-informed decisions.
Detection
Duplicate data can often be a major obstacle in the field of data science. It can lead to skewed results, inaccurate analysis, and inefficient use of resources. Therefore, it is crucial to have effective techniques in place to detect and handle duplicate data. One way to detect duplicate data is by using algorithms such as hashing or clustering. Hashing involves converting data into a unique hash value and comparing these values to identify duplicates. Clustering, on the other hand, groups similar data points together and identifies clusters that may contain duplicates. These techniques help in efficiently identifying and flagging duplicate data for further analysis.Resolution
Once duplicate data is detected, it is essential to resolve the issue to ensure accurate and reliable results. There are several techniques that can be employed to resolve duplicate data in data science. One approach is to simply remove the duplicates from the dataset. This can be done by deleting the duplicate entries or merging them into a single entry. However, before removing any data, it is important to carefully consider the impact it may have on the analysis and the overall dataset. Another technique is to assign weights to the duplicate data based on certain criteria. This allows for the retention of duplicate data while giving it a reduced influence in the analysis. Weighting can be done based on factors such as recency, relevance, or data quality. Using advanced algorithms such as machine learning models can also aid in resolving duplicate data. These models can learn patterns and similarities in the data and provide suggestions on how to handle duplicates effectively. By leveraging the power of automation and intelligent algorithms, data scientists can streamline the resolution process and ensure accurate results. In conclusion, dealing with duplicate data is a critical step in the data cleaning process. Through effective detection and resolution techniques, data scientists can eliminate the negative impacts of duplicate data and obtain reliable insights for their analysis. By employing these methods, data scientists can enhance the quality and accuracy of their data, leading to better decision-making and improved outcomes.Ensuring Data Consistency
Ensuring Data Consistency is a critical aspect of data cleaning in data science. Inaccurate, duplicate, or conflicting data can lead to erroneous analysis and flawed insights. To address this, various techniques such as standardization and normalization are employed to ensure that the data remains consistent and reliable throughout the analytical process.
Standardization
Standardization involves transforming data to a common format, thereby removing inconsistencies that may arise from different sources or input methods. This process ensures that all data elements are uniform, facilitating accurate comparisons and analysis.
Normalization
Normalization is the process of organizing data to reduce redundancy and dependency. By minimizing data duplication and inconsistencies, normalization enhances data consistency and integrity, resulting in more accurate and reliable analysis.
Advanced Techniques In Data Cleaning
When it comes to Data Science, advanced techniques in data cleaning are crucial for accurate analysis.
Machine Learning Models
Machine learning models can help identify and correct errors in data efficiently.
Automated Cleaning Tools
Automated tools like OpenRefine simplify the data cleaning process.
Maintaining Clean Data
Data cleaning is crucial in data science. It involves removing errors and inconsistencies.
Continuous Monitoring
Regularly check data quality to detect any issues promptly.
Updating Cleaning Processes
Modify cleaning methods based on new data patterns or problems.
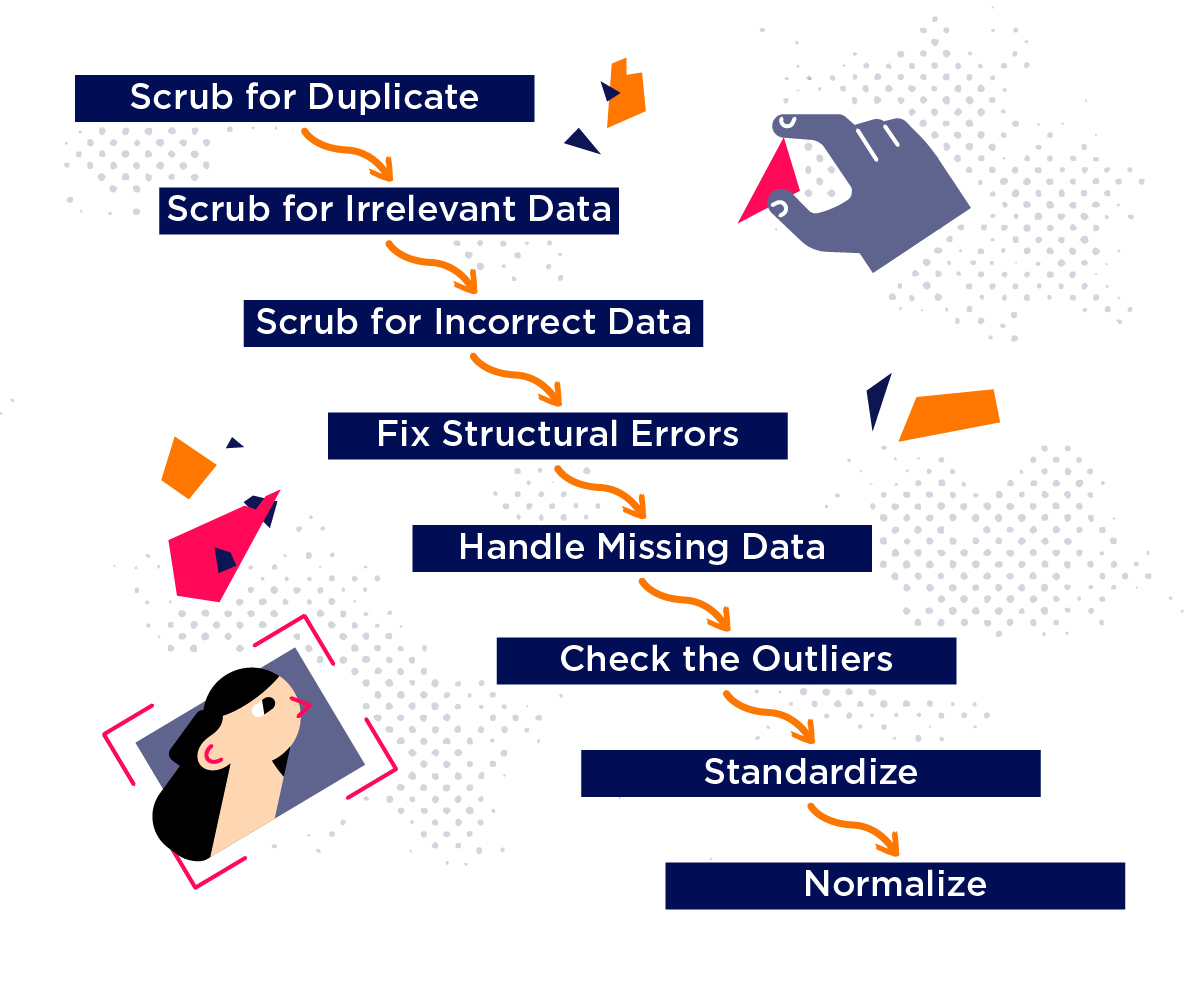
Credit: www.iteratorshq.com
Frequently Asked Questions
What Are The Data Cleaning Techniques?
Data cleaning techniques include removing duplicates, correcting errors, handling missing values, and standardizing formats to ensure data accuracy and consistency.
What Are The 5 Concepts Of Data Cleaning?
The 5 concepts of data cleaning are: 1. Removing duplicates 2. Handling missing data 3. Standardizing data formats 4. Correcting errors 5. Handling outliers
How Do Data Scientists Clean Data?
Data scientists clean data by identifying and removing errors, duplicates, and irrelevant information. They also handle missing data by either imputing or removing it. Techniques like data profiling and visualization help in identifying anomalies, and data is then transformed using techniques like normalization, standardization, and discretization.
How Are Data Cleaning Done In Etl?
Data cleaning in ETL involves removing errors, inconsistencies, and duplicates from the data. This is achieved through various techniques such as data profiling, standardization, validation, and transformation. These processes ensure that the data is accurate, complete, and reliable for further analysis and reporting.
Conclusion
Data cleaning is a crucial step in data science that involves identifying and handling errors, inconsistencies, and missing values. There are various techniques that data scientists can use to clean their data, including data profiling, data deduplication, and outlier detection.
By employing these techniques, data scientists can ensure that their data is accurate and reliable, which is essential for making informed decisions. With the increasing importance of data in today’s world, mastering data cleaning techniques is a must-have skill for any aspiring data scientist.
